QA-ing Client-Side & Server-Side Experiments
QA in client- and server-side experiments ensures accurate, reliable results. 12 experts weigh in on how to streamline QA for flawless execution in a full-stack approach.
Key points:
- A holistic approach to QA ensures every layer of your experiment, from the user interface to backend data tracking, functions as expected.
- Client-side QA focuses on user-facing issues like layout and performance while server-side QA tackles backend processes like API calls and data integrity.
- Feature flags allow for controlled rollouts and isolated testing, making them invaluable for both client-side and server-side QA.
- Post-launch monitoring and retesting are crucial final steps to catch issues that may arise after your experiment goes live.
Ever had a hidden bug ruin your entire experiment?
Imagine a backend disconnect causing data to go out of sync or a front-end flicker revealing the control version before the page loads.
These seemingly minor issues can completely perforate the integrity of your test results and wipe out weeks of effort—not to mention shake your stakeholders’ confidence in your experimentation program.
That’s where QA in experimentation comes in. But while many focus solely on client-side QA, the server-side aspect often gets overlooked.
In this guide, we draw from the collective real-world experience of 12 product, CRO, and marketing experts and their teams to provide a complete approach. We’ll go beyond the usual checks that ensure variants look and behave as intended in an omni-channel ecosystem, and dive deep into server-side QA as well.
Let’s get into it.
What Is Quality Assurance (QA) in Experimentation?
Quality assurance (QA) in experimentation is a comprehensive process that ensures every layer of your experiment—whether it’s client-side or server-side—functions as intended. In this context, QA guards the integrity of your test, from how it looks to how it functions when it goes live and, crucially, how it’s measured.
Throughout this article, we’ll refer to experiment QA in the full-stack sense. This means we’re not only making sure things look and behave as designed but also that the engine under the hood—like data measurement and control—is running correctly.
In line with this thinking, some of our contributors even emphasize that experimenters should maintain granular control over who gets exposed to A/B tests. The same system that facilitates such a level of control can also be used to QA both client- and server-side deployments.
That system is feature flagging.
In product development and experimentation, this is less alien and less of an afterthought since the agile model has injected QA into the very DNA of software development.
Feature flags have become invaluable to QA. Here’s why:
- They allow you to expose variants to QA testers without needing additional code using the same experimentation delivery platform.
- With feature flags, you get to simulate segmentation and specific conditions (location, browser type, etc) that trigger tests. It thus goes beyond randomly checking the execution for bugs and becomes a strategic, pre-deployment feedback choice.
- Feature flags can toggle on specific features for isolated QA-ing, without conflicting influences.
- Experimenters can also QA tests in different environments, like staging and beta.
Now, how does QA for experiments differ from traditional QA for product features about to be shipped?
For one, QA in experimentation is about validation within a complex system, not just functionality. While product QA’s focus is validating feature functionality, experimentation QA ensures that variations perform as designed within the broader ecosystem of user behavior and data measurement.
You’re testing not just how something works but also who sees it and how it impacts conversions, clicks, and engagement.
So far, we’ve drawn plenty of parallels between QA in experiments and software development practices. But…
Software Testing Does Not Replace Experimentation QA
This section is led by insights from Anastasia Shvedova (Lead Consultant – Product Experimentation), Christian Knoth (Front-End Engineer), and René Link (Head of Quality Management) at konversionsKRAFT.
First off, what is the purpose of QA? Why is the QA process even important?
We can all agree that QA is uncomfortable. Developing software, releasing new features, and improving the UX are all exciting, but dealing with side effects, potential issues, and bugs is not.
That’s why many shy away from it—it’s unpopular, slows down the release process, and requires extra steps. Many excuse this by saying there are “no resources” while ignoring the potential consequences.
As a result, they often only focus on software tests (if at all) because these can be automated, creating a false sense of security for peace of mind.
But without proper QA tests, you’re risking:
- Negative long-term product perception: When things don’t function as expected, users become skeptical of the product’s reliability, which has a negative long-term impact.
- Questionable results: If goals—such as tracking user actions and KPIs—are not tested correctly, the results become unreliable. Issues like goals being triggered by the wrong actions, triggered too late, or being placed in the wrong section can lead to inaccurate tracking. Forgetting to track certain goals altogether only worsens the problem. In an A/B testing scenario, this can affect the comparability of goals between the variants, making it difficult to determine which version performs better.
So, a great success formula incorporates software tests with exploratory testing on the QA side. They have different contents but follow a similar process.
QA testing primarily focuses on user experience and interface integrity. This includes checking whether everything works as intended and is visually in place. Does the layout appear as intended? It’s essential to put yourself in the user’s shoes and creatively think about their journey, ensuring that every goal is tracked and compared logically.
Some of the key tasks involved with QA tests are:
- Checking the visual integrity (e.g., paddings, button placements)
- Ensuring that goal tracking is accurate
- Conducting logical comparisons
- Exercising creativity to simulate different user journeys
Meanwhile, software testing (specifically, component testing) will verify and validate the functionality of specific elements on the page. For instance, does a button perform as expected?
Software tests already run alongside or after deployment (depending on the model you’re using) on each stage environment until they reach the live servers, which ensures that functional issues can be avoided and are caught early.
For large ecommerce departments, software testing is a must, especially when testing in a native environment. Software tests ensure the stability of core elements like forms, buttons, and loading speeds, which contribute to overall page performance.
Key focus areas of software testing include:
- Checking the performance of individual elements (e.g., buttons, forms)
- Testing in native environments
- Continuously running tests to catch issues during ongoing tests
While an exploratory QA can sometimes cover the ground addressed by software tests, the reverse is rarely true. The unique value of automated software testing lies in the ease and precision it provides for specific page elements.
Human-Led, User-Centered QA in Experimentation Is Indispensable
While software tests are vital, they cannot replace the nuance and insight brought by QA. Trust, for instance, is something that only a human can evaluate. A user-centered QA process doesn’t just check if a goal is fired but also whether it makes sense in context.
Not all use cases are black and white, and many require interpretation. Certain issues arise because of conceptual misunderstandings or ambiguous user journeys that aren’t always clear at the outset. This is why a user-centered approach is so valuable—rather than following a fixed path like software tests, user-centered testing aims to break out of the typical customer journey to discover hidden issues.
A machine may check if a button appears in the correct spot, but only a human can judge if that button fits aesthetically with the background. Similarly, QA experts can seek out edge cases—use cases that are atypical or outside the norm—and provide meaningful feedback that a software test might miss.
For example, a software test could confirm that a button appears at the right time, but only a human tester can decide if the button is clear, easy to understand, and fits the design of the page.
Because experimentation typically doesn’t occur within the scope of routine tasks or functional tests, you’d mostly rely on QA. The motivation behind your work lies in the emotions of the users surfing the web, which is why you must prioritize human judgment over machine evaluation when assessing results.
Use cases for experiments focused on functional innovations should be evaluated beforehand or through other means (e.g., smoke tests, labs). Once a decision is made to proceed, functional tests should be developed in parallel.
In principle, there should be no distinction between functional and emotional use cases. With this in mind, functional tests cannot match the value of human-led QA.
For long-term quality, keep unit, integration, and end-to-end tests anchored in CI/CD pipelines rather than removing them as exceptions.
QA-ing Client-Side Experiments
Corey Trent, Director of Optimization and Analytics at Convincify, shares a unique perspective on QA-ing client-side experiments:
When QA’ing any test, you must change your mindset and look for ways to break the experience.
Have you ever watched your parents or grandparents frustratingly use the internet, navigating around in ways that completely baffle you? That needs to be your approach to QA. Submit forms incorrectly, click on buttons multiple times, click on things not directly in the center, use stuff out of order, etc.
The number one thing I see experimenters get wrong in QA is just to breeze through an experience thinking people will use the site perfectly, just like they do. People use web pages in bizarre ways, and you must break out of the usual to ensure your experiences are completely stable.
Amrdeep Athwal adds,
Proper QA needs someone insidious who is actively trying to break the experience. For example, does your new form accept negative values or Russian characters or users with just a two-character surname? Edge cases are small, but enough of them start to add up.
— Amrdeep Athwal, Chief Experimentation Officer of Conversions Matter
Quality Assurance Checklist for Client-Side Experiments
Before diving into the client-side QA, let’s recognize the unique challenges of testing on the front end. Here, you’re dealing with user-facing changes that need to look and function as intended — across devices, devices, and network conditions.
Yes, the test runs, but you want to ensure zero visual bugs, flickers, or performance issues.
1. Understand the user flow and document edge cases
Think of this step as making sure you, your team, and any other stakeholders are all speaking the same language.
The first thing you do is run through the user journey to grasp every click, scroll, and interaction. This step isn’t just for you—pull in the combined imaginative power of your team.
Before you do anything else, immediately do a basic run-through to make sure you understand the flow of what you’re testing.
Confirm your understanding with your team.
Once it is clear in your mind, write up your test plans and document the happy path (the ideal user flow) and edge cases—we’re testing for how the system handles unexpected behaviors, too.
Of course, you’ll be on the lookout for big, obvious errors, but don’t forget to spend time assessing responsiveness and ease of use. Document all of these, and remember, a clunky experience isn’t a sticky experience unless.
It’s ideal if you’re using a collaborative tool to document — something like Notion, Jira, or Trello is great to track everything and make sure nothing falls through the cracks.
— Hannah Parvaz, Founder of Aperture
The happy path is like your perfect Saturday morning with no traffic. But every day isn’t Saturday. Users browse differently, click back, refresh and take unexpected routes. Testing should ensure your experiment holds up under all scenarios.
The area that gets overlooked the most is tracking all of the user actions relevant to the experiment. Even if the test gets launched correctly, having a process for QA to test tracking for all variations will save you much frustration.
— Kalki Gillespie, Senior Product Manager at NerdWallet
So, pay attention to negative scenarios and edge cases. For example, what happens if someone tries to submit a form without entering any data? Does your test still hold up, or does it break?
Or what happens if your promo that activates when a user exceeds a $500 value meets an order value of exactly $500? Document everything.
Again (because it’s vital)…
Remember that QA is a team effort. Communicate your findings with the relevant stakeholders and be prepared to retest — that’s why we love automation.
— Hannah Parvaz
Corey Trent highly recommends recording your QA sessions. It is extremely useful for a developer to see exactly what you did to trigger an error, and it can often give them critical details that a screenshot cannot.
2. Test across devices, browsers, and network conditions
Different users, different devices, different experiences. It’s not enough to test on your Macbook Chrome browser alone.
Make sure you are allocating the correct amount of attention to the devices most of your users are accessing your site with. It can be a pain to test on mobile devices; it is important not only to test thoroughly but also to ensure QA is on real devices. Just shrinking your browser to mobile size is not good enough because mobile phone devices and browsers operate very differently from desktop ones.
We’d highly recommend using one of the many cross-device testing tools out there, but make sure they give you access to real devices, not emulators. We use BrowserStack internally, but there are many other good providers out there, such as Saucelabs or Lambdatest.
— Corey Trent
3. Verify targeting, segmentation, and test tool setup
Double-check that your test audience is targeted correctly and that the A/B testing tool’s goals, targeting, and segmentation are all set up properly.
Here are the three biggest things I manually verify:
- Unique participant and conversion counts: Did the number of users you manually pushed through the funnel reflect back to you in your dashboard on both the entry and conversion sides?
This is crucial because, at the end of the day, it’s the building block on which every other bit of complexity starts, and your final read on the experiment is based.- Distribution: Did the variant bucketing occur correctly?
There are two ways to manually test failures in variant assignment: forced variant assignment and random distribution.
Forcing the variant assignment will quickly reveal any obvious problems in server-side logic the devs can jump on quickly.
Testing the random distribution is a bit harder and is more difficult the fancier you get with your splitting rules. Generally, I pour a big cup of coffee and hit the test over and over, about 100 iterations, making sure that each path I go down is using a new user (either incognito browsers if I’m relying on the SDKs or getting the engineers to help me by discarding any identity permanence temporarily while I test).
If you’re utilizing any acceleration features in your experiment that help get you a readout faster based on winning variations, I make sure to turn that off so I’m getting a very straightforward randomization, then turn it back on when I’m ready to launch, as that feature is largely based on any variant assignment code the server-side may have.- Segmentation & Exclusion: Did my test users appear in the correct segment or have the right properties for me to segment with later?
At the bare minimum here, I’m looking to make sure that the data exists and is attached to the user correctly in the dashboard.
If this works, I am confident I’ll be able to set the experiment up in the dashboard to exclude the users or segment them when I’m ready to execute the test.I find that if these three things all work as intended, the vast majority of experiment-ruining problems will be taken care of.
— Ken Hanson, Technical Product Manager at K2 Cyber
4. Check for race conditions
Always look for race conditions (e.g., bucketing a user into an experiment before they have seen the elements being tested).
— Kalki Gillespie
Race conditions can be the silent killers of experiments. They occur when the timing of events causes a conflict.
QA your experience multiple times per device. We have observed problematic test codes where issues only present randomly. Many times, this comes down to a race condition with JavaScript, especially on sites where you might be delivering content dynamically or in a single-page application environment. As a rule internally, we QA each experience at least 10 times for primary devices to try and avoid these deployment issues.
— Corey Trent
5. Check for interactions with dynamic elements or personalizations
Picture this: Your test looks perfect in QA, but suddenly you’re getting reports of broken shopping carts, vanishing buttons, and scrambled analytics. What happened?
Corey Trent has seen this scenario play out many times:
Many web platforms have made it easy to have highly personalized websites, which can cause issues with how your test code interacts on pages under particular circumstances.
For any sections or pages part of this test, you need to assess whether there are any dynamic elements or personalizations for certain conditions we need to account for. For example, do certain portions of the page change based on user type, traffic source, etc.?
6. Ensure the test code doesn’t break other elements
Your website is a delicate ecosystem – touch one thing, and you might unintentionally disrupt something seemingly unrelated on the other side of the page. This is why seasoned optimizers check everything, not just what they meant to change.
Corey recommends,
For every page your experiment code runs, you need to QA everything on the page, even things you do not think your changes affected. A lot of optimizers get into trouble just focusing on the exact areas their experiment changes are targeting, but we’ve seen many times where JavaScript or CSS rules break other non-related items on the page and go unnoticed.
There are many ways your experiment code can intermingle with different elements on the page by accident, and it might not be immediately apparent that your code is breaking things.
7. Handle visual and performance issues: flicker effect, page speed, and layout
Always check for a flickering effect, which may only affect the variation and confound your results!
— Kalki Gillespie
Flicker can wreck your test results. Ensure you’re using a zero-flicker A/B testing tool.
You also want to validate the typography, colors, margins, and padding across devices to ensure the design holds up. The experience has to be consistent between your control and variants, or else you’ll unknowingly introduce a new variable and skew your results.
When making large changes, keep an eye on load times with your test experiences.
While A/B testing will always have some impact on page load time or the perceived load, there should not be extreme variance in how long people are waiting for the page to render between experiences.
This variance becomes an extra variable in your test and could materially impact performance. You can employ many coding tricks to avoid this, which you might need to get creative with depending on what you are testing. Many browsers will have methods to access this data, or you can use tools like PageSpeed Insights.— Corey Trent
Having automated client-side testing that measures page speed metrics, such as first contentful paint, separately between variations, will let your team consider this as an afterthought. But you should check for EVERY test!
— Kalki Gillespie
8. Check for external factors and concurrent tests
When running experiments, it’s not just the test itself that matters—you have to be aware of everything else happening on your site that could affect your results.
External factors like major sales events or holidays can flood your site with unusual traffic patterns that don’t represent normal user behavior.
For instance, a Black Friday promotion could skew the engagement data, making it hard to gauge how users would respond to your variations under regular conditions.
Also, running multiple experiments in the same area of your site can create interference and second-order effects, as users could be exposed to several variations at once. This can lead to conflicting data and render your results unreliable.
Before you launch that test, double-check if other tests are running in overlapping areas or targeting the same user segments. Keep your test free from external noise.
9. Retest and monitor after launch
Launching the test is just the beginning.
Once live, we repeat the same steps using the live test URL. The internal and post QA’ing is done by the testing developer and by the Hype CRO team to ensure there is more than one set of eyes.
— Emily Isted, Head of Experimentation @ Hype Digital
This process ensures that the live environment functions correctly, and it’s crucial to involve more than one person in post-launch QA to catch any issues that may surface once users interact with the test at scale:
Failing to monitor after going live can result in missing issues that only surface in the production environment, potentially leading to significant problems if not addressed promptly.
— Laura Forster, Business Unit Lead at UpReply
Besides, re-QA-ing your live experiment confirms that changes to the backend or site don’t introduce new issues that weren’t present in pre-launch QA.
Use tools like feature flags to quickly toggle off problematic variations without disrupting the entire experiment.
QA-ing Server-Side Experiments
Many experimenters would agree server-side QA is a different beast.
While client-side experiments are all about what the user sees and interacts with, server-side QA focuses on what’s happening in the engine—handling data processing, logic, and infrastructure stability.
The challenge with server-side QA lies in its complexity and the technical know-how required. With feature flags, race conditions, and custom code to consider, server-side QA requires close collaboration between QA teams, developers, and product managers.
Quality Assurance Checklist for Server-Side Experiments
Here, we’ll be testing to ensure every backend process, from API calls to data storage, functions as designed. This is how you guarantee your server-side experiments are accurate, reliable, and resilient under real-world conditions.
1. Define test cases and specify the sequence of events
Before you even begin QA, clearly outline the sequence of events that your test will follow, from the first API call to the final data storage.
Defining the test case for each test and specifying the sequence of events, API calls, and elements viewable in the viewport will arm your QA team with everything they need to catch bugs early.
— Kalki Gillespie
This means considering what elements users will see, how the server will handle requests, and ensuring that each step flows in the correct order.
For example, if you’re testing a new recommendation engine, you’ll want to define the exact API calls that fetch data, the user actions that trigger those calls, and the expected server response.
Without this kind of detailed blueprint, your QA team is left guessing, and that’s where errors can slip through unnoticed. Laying everything out in a flowchart speeds up the QA process and ensures every action and step is accounted for.
2. Ensure precise measurement and accurate data tracking
Ken Hanson of K2 Cyber said it best: The most important thing before greenlighting a server-side test is the precision of measurement.
This is usually the culprit for most headaches when split testing and can cause a whole experiment to need to be restarted, wasting valuable time and (if uncaught) potentially causing a bad decision to be confidently made.
This risk is a bit higher than normal once you’re server-side because the flow of tracking begins encountering custom code.
To feel completely confident, I like to work up from simple to complex, and I do it through manual verification. It can be a slog, but it’s worth it if you’ve ever had to trash an experiment.
I find it much easier to do manual verification by setting up a “clean room” environment, where I’ll isolate the test to a path only I can get to or work with the devs to provide me hooks to force things.
I’ll only add team members to the QA effort once I feel confident with my own manual verification.
The important thing to do during this manual verification is to record your numbers manually as you go so you can independently verify what you see in the dashboard.
— Ken Hanson
Convincify’s Corey Trent points to another critical consideration for testers: If you are making large flow changes on your site, make sure these modifications are not breaking how your paid marketing team might be tracking site goals, and not going to destroy analytics reports.
If you are going to run a redirect test, collect a couple of the most complex URLs in the test experience. For example, a page URL with many paid search tracking query parameters, and ensure your redirect logic keeps the links intact. E.g.
www.yoursite.com/test-page?fbclid=24929842908280428080248042&utm_medium=fb_feedad&utm_source=fb&utm_campaign=summersale&rcclidif=29482041nflafoi29nal;safliwf
We’ve seen people get in trouble with their redirect tests, where their setup/code is breaking traffic to the page where the URL might have extra query parameters on it.
3. Ensure proper frontend-backend integration
For full-stack QA, testing how the frontend and backend interact is a cornerstone process.
According to Tasin Reza, COO of EchoLogyx, one common pitfall is when frontend actions, such as adding a product to a cart or submitting account details, don’t properly reflect backend updates.
For example, while testing an “Add to Cart” functionality, the frontend must display correct product details—such as name, price, and quantity—while the backend must accurately update stock levels and ensure consistency in the database.
When these actions don’t sync, we experience situations where a product appears available on the frontend but is actually out of stock on the backend. This data inconsistency can disrupt the user journey and harm conversions.
Another important scenario Tasin shared is user account creation. Proper integration ensures that when users register and receive a success message on the frontend, their account is also properly stored and authenticated on the backend.
Missing these vital backend updates is usually the cause of problems like successful registration notifications without actual account creation. You can imagine the confusion that’ll arise during login or checkout.
That is why ensuring consistent communication between frontend and backend layers, validating database changes, and proper error handling on the frontend is vital in server-side QA.
4. Use feature flags to control the rollout
Feature flags give you the ability to decide exactly who sees what and when with your experiments. They can be much more than toggles when used right:
Ensure you have a system in place that allows you to have full control over who sees what and when, and integrate that system with your continuous live delivery flow, allowing you to use the same exact system in live to do QA testing before exposing anything to your end users.
I just basically described the key functionalities of a full-fledged feature flag system but with the added powers of being part of your CD system (nothing goes live without a feature flag, including hotfixes).
I prefer to call them a remote feature management system when they offer more than a simple “on/off toggle” and a key-value store. Because by controlling who can see your new development, you can very easily target whoever is doing your QA-ing, independently of the moment, whether it is on the client or server side.
Bonus tip: Integrate your A/B testing system with it, and you will have superpowers — now you can test everything that your team deploys progressively, always under control and data-driven. The best QA-ing system in the world.
I’m such a believer in that philosophy that we built our system internally with those functionalities in mind, and it drove us from 8 to 80 in the speed of delivery and reducing the number of errors, but with the increased confidence from the teams because the time to rollback from any detected issues became seconds to minutes vs. hours to days.
It took less than 6 months for our nearly 50 engineering teams to start using our system exclusively, both on new and old code.
— Luis Trindade, Principal Product Manager at Farfetch
It’s a big plus if your A/B testing tool has feature testing features, allowing you to use feature flags for granular control. Specimen A: Convert.
As Trindade notes, this approach dramatically improves speed, reduces errors, and transforms the way you handle deployments.
The ability to reverse changes in seconds rather than hours or days builds trust across engineering teams and helps prevent major disruptions.
Without sufficient data, even the best experiment can fall flat, leading to misleading insights or inconclusive findings.
Mistakes to Avoid When QA-ing
Even the most thorough QA processes can fall prey to common mistakes that derail experiments and lead to inaccurate results.
Here are the most common ones experienced experimenters talked to us about:
Too Much Reliance on Automated QA Testing
Moving towards automation as quickly as possible is key. It saves both time and reduces human error, so once your process is established, automate everything you can.
— Hannah Parvaz
That is sound advice. Automate QA when you can, but don’t forget about manual QA testing.
You can automate repetitive checks (such as cross-browser functionality), but be sure to manually test edge cases and scenarios that automated tools might miss. Be especially mindful of user interactions like incorrect form submissions or erratic clicking.
Important: Don’t be solely reliant on the QA or debugging feature of your A/B testing tool. It should be just one tool in your toolbox.
Never trust the QA mode of A/B testing tools; it’s never 100% reliable. Instead, set the test live to a specific cookie, URL query parameter, or whatever. URL query parameters work well as the link can be shared easily.
— Amrdeep Athwal
Corey Trent warns about over-reliance on automated testing too:
While automated QA tools can save time finding high-level, obvious problems, they can instill false confidence. These tools can often miss issues that happen infrequently or when users do something unexpected.
QA Testing in the Wrong Environment
Corey says you should test as much as possible like a real user would:
Do not be logged into any CMS, internal IPs (if possible), or marketing platforms. While logged in, many QA environments or content management systems will render your site differently than production. We have seen numerous times where things will pass a QA look when reviewing in these environments, only to launch with multiple issues absent in prior QA on these non-production environments.
Poor Internal Communication
Optimizers fail to build partnerships with QA and engineers, assuming that they’ll organically understand what to look for, leading to tests getting launched only to find out that there’s something wrong with the implementation. Which causes disappointment and delays.
— Kalki Gillespie
Corey Trent recommends establishing clear communication channels:
Many of our clients have multiple ways their website code can change, with developers changing the site, tag management platforms, or even the marketing team using tools to inject email modals or sale banners. These items can potentially break your test code in ways not seen during the original QA.
It is critical that your organization has good communication when changes on the site happen, and if you need to, quickly go through a brief re-QA to ensure there are no issues with your live test.
Typically, we suggest always maintaining a dashboard of active tests people can view (e.g., Kanban in Trello) and having a chat channel or email list notified when changes are pushed live by anyone internally and where.
Scope Creep During QA
QA isn’t a time for last-minute ideas to pop in.
Introducing new requirements during the QA phase can cause delays and testing loops, which should have been addressed in the initial specification.
— Laura Forster
These changes should have been accounted for in the initial specification to avoid bottlenecks.
Stick to the defined scope during QA to keep the process streamlined and avoid unnecessary complications.
Deprioritizing QA
Drawing from years of optimization experience, Corey Trent paints a sobering picture of what happens when QA takes a backseat:
A robust QA protocol is one of the most essential aspects of keeping your experimentation program alive. We’ve seen numerous times where just a few large QA slip-ups cause an organization to become nervous around testing, and it becomes the first thing to blame for any performance issues.
In extreme cases, we’ve seen it even put the experiment program in jeopardy of being shut down due to risk. You want to avoid this at all costs, and while it is not the most fun work, QA is extremely important to your optimization efforts.
Tips for QA Testing (Client-Side and Server-Side)
Let’s explore three essential considerations before you begin your QA process:
1. Don’t Forget to Test Different User States
Corey recommends testing all use cases with your changes if you have different user states on your website or mobile app (e.g., membership tier, logged in vs logged out).
It goes without saying that the experience may be different for these distinct user states in ways that may not immediately come to mind. And that might add a confounding variable to your experiments.
2. Do Not Limit Your QA to the Tested Elements
Thorough QA extends beyond your immediate changes. Corey emphasizes testing the entire user journey:
Test other critical things in the user journey that go beyond the immediate feature or site change you made. Many of our clients employ server-side testing to make large structural changes to a website or a mobile app (e.g., new search provider, new CRM, recommendation engine, checkout flow, etc.). What might not be apparent is that these changes interact with other areas of the journey, not just the immediate pages we’re testing on. For example, if we’re testing a new product search engine, are the product details correct when you add to the cart? Is the right product image used? Can you buy that product you added to the cart, or does the checkout error out?
3. Test Your Pages With a Slower Connection
The order in which the browser loads items into the page and completes them can change quite a bit when users have slower internet, which can cause problems with your test code.
As a rule of thumb, we’ll look at the test experience with 4G internet connection speed to ensure no issues arise. Developer tools on many of the large browsers have this as an option. On mobile devices, many of the remote testing platforms like BrowserStack and DevTools allow you to throttle the connection as well.
— Corey Trent
4. Ensure sufficient site traffic for reliable results
One of the most common A/B testing pitfalls in experimentation is launching a test without enough traffic to generate statistically significant results.
No matter how remarkable your test design is, it won’t give you valid conclusions if enough users aren’t exposed to it.
To avoid this, make sure there’s enough traffic flowing through your experiment to allow for meaningful analysis. The more users interact with your variations, the clearer your results will be.
And if you don’t have enough site traffic, there are other ways you can approach optimizing your site.
Learn more: How to A/B Test on Low-Traffic Sites
Convert’s QA Tools for Error-Free Experiments
Learn More: How Convert Overcomes Typical QA Challenges
At Convert, we offer a range of tools that help you integrate QA into your workflow with ease.
From debugging scripts to testing variations in real-world conditions, these tools remove the guesswork and move you closer to flawless experimentation execution.
QA Overlay

The QA Overlay integrates into your Convert experiment summary, allowing you to validate experiments directly within a live environment.
Currently exclusive to Chrome browsers (with support for other browsers planned for the future), this feature requires the following:
- The Convert Chrome extension installed
- The latest Convert tracking script implemented on your site

This widget is part of your variation preview options, giving you link access (with a QR code as well) to different variations so you can quickly preview the variations on various devices. You can then switch between variations and original versions (note: page reload is required when switching between any variations or the original).
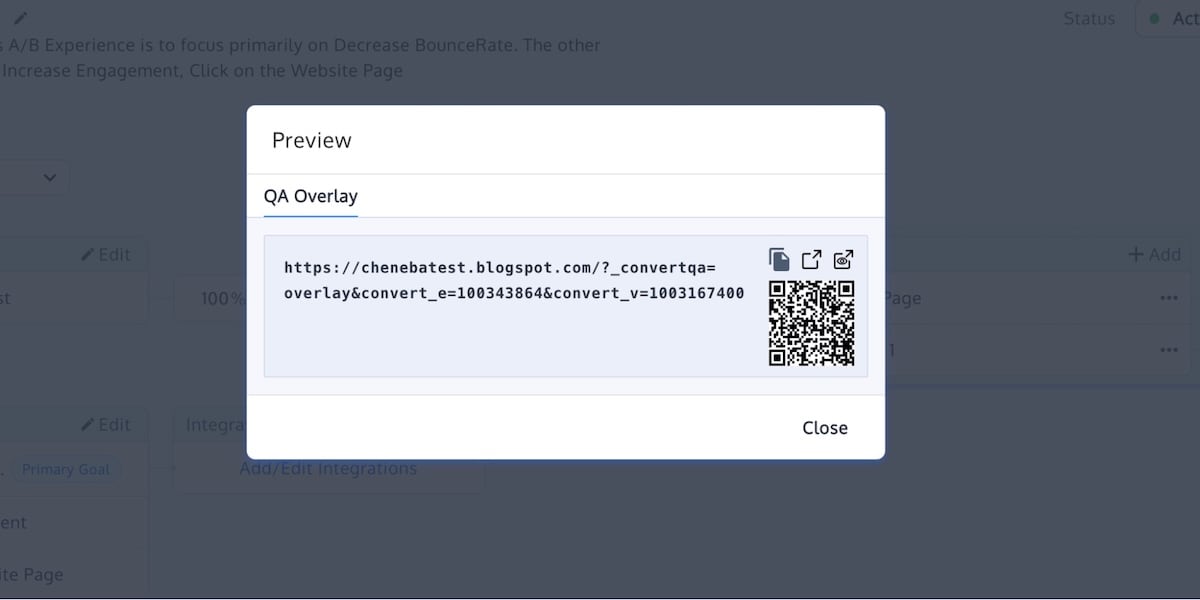
This link also takes you to a browser window where you can view experiments currently running, audiences, pages, goals, live logs, project ID, details about variations, etc. — the tools and data you need to QA experiments in a live environment.
The live logs feature, for example, tracks active experiments and goals in real time, allowing you to get quick status reports for each variation.
The status overview informs you about the health of your integration. Is your tracking code installed correctly? Are your experiments actually running? Is the snippet in sync?
But that’s not all. You can do these checks for different projects at the same time. This adjustable QA overlay panel will show you all the projects you’re currently running and how long each check lasts before the session expires.

The QA Overlay is a solid QA ally, supporting your work with detailed information about your experiment so you can quickly verify it’s running correctly while it’s live.
The Chrome Debugger Extension

Convert’s Chrome Debugger Extension outputs detailed logs to the Chrome Developer Tools console. It gives you real-time insights into how your experiments are behaving.
You’ll see which experiments and variations are triggered so you can trace the sequence of events for a smoother debugging process.
Use this tool throughout your QA process to verify if you’re bucketed into the correct experiment and variation. A common mistake people make here is getting bucketed into the original variation and thinking the experiment isn’t working. But if you enable the extension in incognito mode, that’ll solve the problem.
Preview Variation URLs

When working in Convert’s Visual Editor, Preview Variation URLs allow you to switch between variations to see how they look. They aren’t a substitute for actual QA-ing.
Since they don’t consider Site Area or Audience conditions, Preview URLs are simply a quick way to verify design changes.
You’ll find the Preview URLs generated for each variation in both the Visual Editor and reporting dashboard, marked with an eye icon for easy access.
Forced Variation URLs

These URLs allow you to test your experiment in an environment that closely mirrors what real visitors experience. Forced Variation URLs evaluate your experiment’s conditions—like Site Area and Audience—ensuring that everything is functioning as it should.
Forced Variation URLs are served from the same CDN server used for live visitors, providing a realistic test environment. It’s the best way to confirm your experiment is ready to launch without affecting your actual traffic.
Note: When using the latest Convert tracking script, you’ll access these features through the QA Overlay. Forced Variation URLs are available when using the legacy tracking script.
Using Query Parameters for QA Audiences

Convert makes it easy to restrict tests to specific audiences with query parameters. When you add a QA Audience to your experiment, you can run tests internally without exposing them to external users. This keeps your tests contained, ensuring no visitors accidentally trigger an unfinished experiment.
Simply append a query parameter (e.g. ?utm_medium=qa), to your experiment URL, and you’re ready to test. Opening a fresh incognito window ensures you have a clean slate for each session.
Live Logs

Convert’s Live Logs track and display user interactions with your experiments in real time. Accessible from your project dashboard, Live Logs provide insight into when goals fire, which variation was shown, and how users interact with your experiment.
You can even drill down to view details like the user’s device, browser, and country.
Live Logs not only help you monitor conversions but also validate your setup and debug any issues before they escalate.
Everything in a Nutshell
QA-ing your experiments is vital for delivering reliable, actionable insights.
Whether you’re dealing with client-side variations or complex server-side logic, the goal is always the same: ensuring your experiments work as intended, capture accurate data, and provide a seamless experience for users.
Save this checklist for QA’ing your future client-side and server-side experiments:
- Have you documented the ideal user flow (happy path) and all possible edge cases? Is everyone on the team aligned on how the experiment should work?
- Have you tested the experiment across all relevant devices, browsers, and network conditions (including slower connections)?
- Is your test audience targeted correctly? Are segmentation and exclusion rules functioning properly? Are all experiment conditions (site areas, goals, targeting) configured as expected?
- Have you checked if dynamic content or personalized elements behave as expected based on user types, traffic sources, or other variables?
- Does the test code interact smoothly with other elements on the page? Have you checked that JavaScript and CSS changes don’t disrupt unrelated features or tracking pixels?
- Is there any flicker effect when switching between variations? Are the typography, colors, and layout consistent across variations? Have you checked for significant differences in load times?
- Are there any other tests running concurrently that could interfere with your results? Have you considered external factors like high traffic from sales or holidays that might skew data?
- Have you repeated the QA steps after the test went live? Are you monitoring the live environment to catch any issues that surface in production?
- For server-side QA, have you clearly defined the sequence of events, API calls, and conditions needed for the experiment to run smoothly?
- Have you tested the experiment multiple times to ensure there are no race conditions where events happen in the wrong order?
- Is your data tracking working accurately? Have you manually verified that the correct data is being collected and reflected in your dashboards?
- Does the frontend properly communicate with the backend? Are user actions like form submissions and cart additions accurately reflected in the backend data?
- Are you using feature flags to gradually roll out the experiment and control which users are exposed to it? Can you quickly roll back changes if needed?
- Do you have enough site traffic to generate statistically significant results?


Written By
Uwemedimo Usa, Corey Trent


Edited By
Carmen Apostu

Contributions By
Amrdeep, Anastasia Shvedova, Christian Knoth, Corey Trent, Emily Isted, Hannah Parvaz, Kalki Gillespie, Ken Hanson, Laura Forster, Luis Trindade, René Link, Tasin Reza










